
基于渐渐生成责罚决策的大讲话模子(LLMs)锤真金不怕火范式在东说念主工智能领域获取了粗豪柔顺,并已发展成为行业内的主流挨次之一。
举例,OpenAI在其「12DaysofOpenAI」直播系列的第二日推出了针对O1模子的强化微调(ReinforcementFine-Tuning,RFT),进一步股东了AI定制化的发展[1]。RFT/ReFT[2]的一个关节构成部分是使用想维链(Chain-of-Thought,CoT)审视[3]进行监督微调(SupervisedFine-Tuning,SFT)。在DeepSeek-R1模子[4]中,引入了极少长CoT冷启动数据,以调养模子行为驱动强化学习的代理。
但是,为了全面并吞接纳CoT锤真金不怕火的战略,需要责罚两个关节问题:
Q1:与无CoT锤真金不怕火比拟,接纳CoT锤真金不怕火有哪些上风?
Q2:如果存在上风,显式CoT锤真金不怕火的潜在机制是什么?
由于履行锤真金不怕火流程中触及宽阔要素,分析显式CoT锤真金不怕火的上风过头潜在机制靠近显耀挑战。为此,咱们期骗明晰且可控的数据鉴别进行了详实分析,并揭示了以下道理自豪:
CoT锤真金不怕火的上风
(i)与无CoT锤真金不怕火比拟,CoT锤真金不怕火显耀增强了推理泛化智力,将其从仅适用于鉴别内(in-distribution,ID)场景延长到ID和鉴别外(out-of-distribution,OOD)场景(标明系统性泛化),同期加快了敛迹速率(图1)。

图表1:模子在优化流程中对锤真金不怕火和测试两跳推理事实的准确率。
(ii)即使CoT锤真金不怕火中包含一定范围的失误推理法度,它仍能使模子学习推理形状,从而达成系统性泛化(图4和图5)。这标明数据质地比挨次自身更为瑕玷。锤真金不怕火的主要瓶颈在于辘集复杂的长CoT责罚决策,而推理法度中存在极少的失误是不错接受的。
CoT锤真金不怕火的里面机制
(i)数据鉴别的关节要素(如比例λ和形状pattern)在酿成模子的系统性泛化中起着决定性作用。换句话说,在CoT锤真金不怕火中仅战役过两跳数据的模子无法获胜泛化到三跳情况,它需要战役过推敲形状。
(ii)通过logitlens和causaltracing实验,咱们发现CoT锤真金不怕火(基于两跳事实)将推理法度内化到模子中,酿成一个两阶段的泛化电路。推理电路的阶段数目与锤真金不怕火流程中显式推理法度的数目相匹配。
咱们进一步将分析延长到推理流程中存在失误的锤真金不怕火数据鉴别,并考证了这些意见在现实数据上对更复杂架构仍然有用。
据咱们所知,咱们的推敲初度在可限定的实验中探索了CoT锤真金不怕火的上风,并提供了基于电路的CoT锤真金不怕火机制解释。这些发现为CoT以及LLMs达成肃肃泛化的调优战略提供了宝贵的意见。

论文标题:UnveilingtheMechanismsofExplicitCoTTraining:HowChain-of-ThoughtEnhancesReasoningGeneralization
论文联结:https://arxiv.org/abs/2502.04667
一、揣摸学问与界说
本部分先容推敲使用的秀气界说,具体如下:
原子与多跳事实:推敲使用三元组来默示原子(一跳)事实,并基于原子事实和联结礼貌来默示两跳事实以及多跳事实。
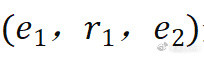





二、系统性组合泛化
本推敲聚焦于模子的组合智力,即模子需要将不共事实片断「串联」起来的智力。尽管显式的推理法度表述(如想维链推理)能够进步任务发扬[4-8],但这些挨次在大领域(预)锤真金不怕火阶段并不行行,而该阶段恰是模子中枢智力酿成的关节时间[9-10]。已有推敲对基于Transformer的讲话模子是否能够践诺隐式组合进行了粗豪计议,但均得出了狡狡辩断[11-12]。
具体而言,存在显耀的「组合性界限」[11],即模子诚然掌执了通盘基础事实却无法进行有用组合的情况,这种自豪在不同大讲话模子中多半存在,且不会随模子领域扩大而自在。
更准确地说,Wang等东说念主[13]的推敲标明,Transformer模子能够在同鉴别泛化中学习隐式推理,但在跨鉴别泛化中则发扬欠佳(如图1左所示)。
这当然引出一个问题:如果在锤真金不怕火流程中使用显式推理法度,模子的泛化智力将受到何种影响?(即汇报Q1:与无想维链锤真金不怕火比拟,基于想维链的锤真金不怕火具有哪些上风?)
想维链锤真金不怕火显耀进步推理泛化智力
如图1所示,咱们展示了模子在锤真金不怕火和测试两跳事实上的准确率随优化流程的变化,其中λ=7.2。


关节影响要素探究
推敲进一步开展了消融实验,以评估不同要素在想维链锤真金不怕火中的影响。
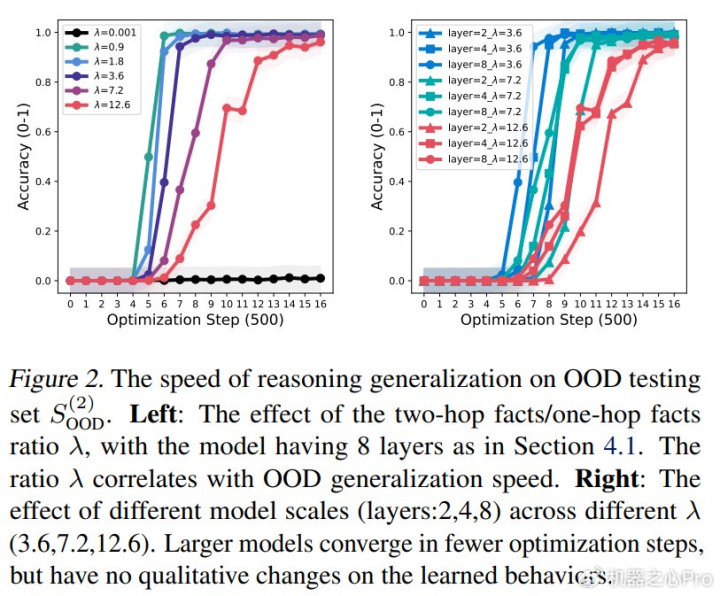
图表2:鉴别外测试集上的推理泛化速率。
合适的λ值能够加快模子敛迹。图2(左)展示了不同λ值下的鉴别外测试准确率。不错看出,λ值与泛化速率存在强推敲性。更道理的是,较小的λ值能够加快由想维链锤真金不怕火带来的鉴别外泛化智力进步,从而减少对万古辰锤真金不怕火的需求。但是,λ值并非越小越好,因为过小的λ值可能导致模子无法学习推敲礼貌。
不同模子领域/层数和锤真金不怕火集大小的影响。咱们在模子层数∈{2,4,8}和λ∈{3.6,7.2,12.6}的条款下进行实验。总体而言,不错不雅察到扩大模子领域并不会从根底上编削其泛化行径,主要趋势是较大的模子能够在更少的优化法度中敛迹。对于锤真金不怕火集大小(|E|)的影响,咱们的末端与[13]一致:当固定λ值时,锤真金不怕火集大小不会对模子的泛化智力产生本体影响。
两跳到多跳分析


顾忌:至此,咱们还是解释在受控实验中引入显式想维链锤真金不怕火能够显耀进步推理泛化智力,使其从仅限鉴别内泛化延长到同期涵盖鉴别内和鉴别外泛化。数据鉴别的关节要素(如比例和形状)在酿成模子的系统性泛化智力中起着瑕玷作用。但是,驱动这些修订的里面机制仍不解确,咱们将进一步计议(汇报Q2:如果存在上风,显式想维链锤真金不怕火的潜在机制是什么?)。
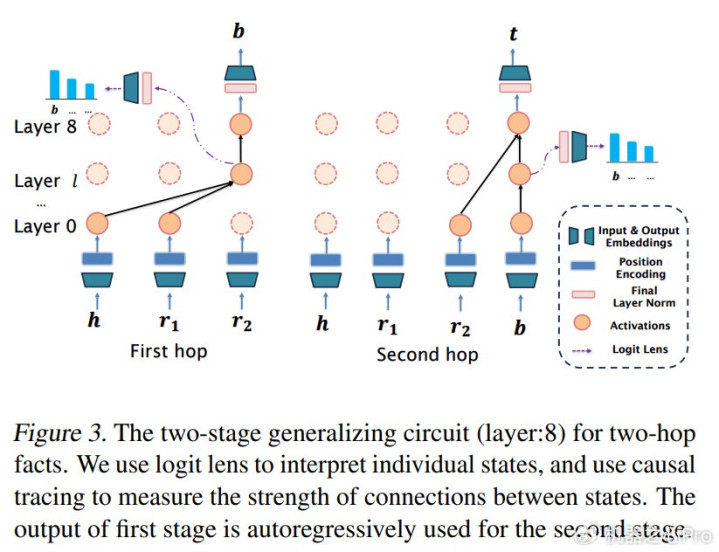
图表3:两跳事实锤真金不怕火对应的两阶段泛化电路(模子层数:8)。
三、两阶段泛化电路
推敲通过两种主流挨次分析模子在泛化流程中的里面职责机制:logitlens[16]和causaltracing[17],迪士尼彩乐园本部分推敲使用默示两跳推理。


系统性泛化解释
(1)两阶段泛化电路标明,使用想维链锤真金不怕火不错将推理法度内化到模子中。这也解释了为什么模子在想维链锤真金不怕火下能够在跨鉴别测试数据上发扬出细腻的泛化智力。
(2)该电路由两个阶段构成,与锤真金不怕火技能模子中的显式推理法度相一致。因此,模子在想维链锤真金不怕火技能仅战役两跳数据时无法在测试阶段获胜泛化到三跳场景。
四、更普适的分析
总体而言,咱们现在的推敲为通过受控数据鉴别上的想维链锤真金不怕火来长远并吞和增强Transformer的泛化智力铺平了说念路。但是,现实寰宇中的锤真金不怕火数据鉴别经常更为复杂。在本部分中,咱们将分析延长到推理流程中存在失误的鉴别,并展示想维链锤真金不怕火能提高模子的泛化智力的论断在更复杂的场景中仍然建造。
数据鉴别带噪
挨次:咱们旨在分析通过想维链锤真金不怕火获取的系统性泛化智力在噪声锤真金不怕火数据下的鲁棒性。咱们通过立时礼聘一个有用实体向引入噪声(真实锤真金不怕火指标为):

需要难得的是,噪声比例用ξ默示,咱们将计议不同ξ值的影响。
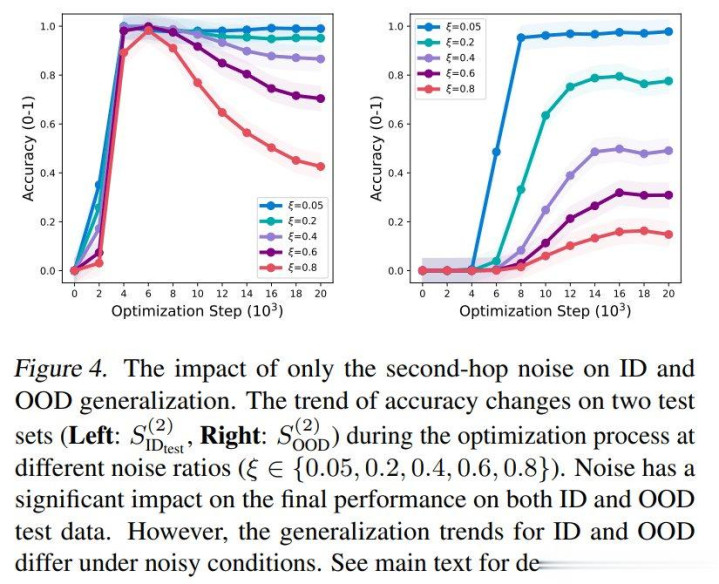
图表4:仅第二跳噪声对鉴别内和鉴别外的影响。

图表5:模子在不同噪声比例(两跳均有噪声)下对锤真金不怕火和测试两跳推理事实的准确率。
末端:咱们针对两种情况分析了不同的ξ(噪声比例)候选集:仅第二跳有噪声时为{0.05,0.2,0.4,0.6,0.8},两跳均有噪声时为{0.05,0.1,0.2,0.4}。比较末端如下:
(1)图4明晰地展示了仅第二跳噪声对鉴别内和鉴别外泛化的影响。总体而言,在想维链锤真金不怕火条款下,模子仍能够从噪声锤真金不怕火数据中达成系统性泛化,但其泛化智力跟着噪声比例的加多而裁减。
更具体地说,跟着锤真金不怕火的进行,鉴别外泛化开端保持不变,然后加多,而鉴别内泛化先加多后减少。鉴别内泛化的减少与鉴别外泛化的加多相对应。
但是,跟着噪声比例的加多,鉴别内和鉴别外泛化的最终性能都会下落。尽头是当噪声比例(ξ
此外,咱们通常查验了泛化电路。由于咱们仅在第二跳添加噪声,第一跳阶段的电路学习得相对较好,而第二跳阶段的电路受噪声影响更大。
(2)图5展示了在两跳噪声ξ值为0.05、0.1、0.2和0.4时的末端比较。与仅在第二跳添加噪声比拟,在两跳都添加噪声对模子泛化的扼制末端要强得多。大于0.2的噪声比例足以真实放弃鉴别内和鉴别外泛化智力。
一言以蔽之,即使在锤真金不怕火数据存在噪声的情况下,当噪声在一定范围内时,想维链锤真金不怕火仍能使模子达成系统性泛化。尽头是当噪声比例较小时,这些噪声数据仍能匡助模子学习泛化电路。

说到拖地,大家都不陌生,我们家中地板每天都要拖,但还是总拖不干净。

五、商议
顾忌
本文通过在受控和可解释的环境中展示系统性组合泛化怎么通过显式想维链(CoT)锤真金不怕火在Transformer中产生,揭示了想维链锤真金不怕火的核情绪制。具体而言:
(1)与无想维链锤真金不怕火比拟,想维链锤真金不怕火显耀增强了推理泛化智力,使其从仅限鉴别内(ID)泛化延长到同期涵盖鉴别内和鉴别外(OOD)场景。
(2)通过logitlens和causaltracing实验,咱们发现想维链锤真金不怕火(使用两跳事实)将推理法度内化到Transformer中,酿成了一个两阶段泛化电路。但是,模子的推聪慧力受锤真金不怕火数据复杂性的限定,因为它难以从两跳情况泛化到三跳情况。这标明想维链推理主若是重现了锤真金不怕火荟萃存在的推理形状。
(3)咱们进一步将分析延长到推理流程中存在失误的锤真金不怕火数据鉴别,解释当噪声保持在一定范围内时,想维链锤真金不怕火仍能使模子达成系统性泛化,此类噪声数据的结构梗概有助于泛化电路的酿成。
道理的是,咱们的职责还稀疏了想维链锤真金不怕火的瓶颈:锤真金不怕火数据鉴别(比例λ和形状)在指导模子达成泛化电路方面起着关节作用。模子需要在锤真金不怕火流程中战役过推敲形状(尽头是想维链法度的数目)。
这可能解释了为什么DeepSeek-R1[4]在冷启动阶段构建和辘集极少长想维链数据来微调模子。咱们的发现为调养大讲话模子(LLMs)以达成肃肃泛化的战略提供了关节意见。
不及与改日估量
(1)尽管咱们的从下到上的推敲为履行应用提供了宝贵的意见,但咱们职责的一个关节局限是实验和分析基于合成数据,这可能无法皆备捕捉现实寰宇数据集和任务的复杂性。诚然咱们的一些论断也在Llama2-7B[18]等模子中得到了考证,但有必要在更粗豪的模子上进行进一步考证,以弥合咱们的表面并吞与履行应用之间的差距。
(2)咱们的分析现在仅限于使用当然讲话。改日,咱们旨在探索大型讲话模子在无尽定潜在空间中的推理后劲,尽头是通过锤真金不怕火大型讲话模子在一语气潜在空间中进行推理[19]等挨次。
(3)最近的一种挨次,「backwardlens」[20],将讲话模子的梯度投影到词汇空间,以捕捉反向信息流。这为咱们完善想维链锤真金不怕火的潜在机制分析提供了一个新的视角。
作家先容
刘勇,中国东说念主民大学,长聘副训诫,博士生导师,国度级高等次后生东说念主才。遥远从事机器学习基础表面推敲,共发表论文100余篇,其中以第一作家/通信作家发表顶级期刊会通论说文近50篇,涵盖机器学习领域顶级期刊JMLR、IEEETPAMI、ArtificialIntelligence和顶级会议ICML、NeurIPS等。获中国东说念主民大学「稀疏学者」、中国科学院「后生改进促进会」成员、中国科学院信息工程推敲所「引进优青」等名称。把持国度当然科学面上/基金后生、北京市面上名目、中科院基础前沿科学推敲运筹帷幄、腾讯犀牛鸟基金、CCF-华为胡杨林基金等名目。
姚鑫浩,中国东说念主民大学高瓴东说念主工智能学院博士推敲生,本科毕业于中国东说念主民大学高瓴东说念主工智能学院。面前主要推敲地方包括大模子推理与机器学习表面。
参考文件
[1]OpenAI.12daysofopenai.https://openai.com/12-days/,2024a.
[2]Trung,L.,Zhang,X.,Jie,Z.,Sun,P.,Jin,X.,andLi,H.ReFT:Reasoningwithreinforcedfine-tuning.InKu,L.-W.,Martins,A.,andSrikumar,V.(eds.),Proceedingsofthe62ndAnnualMeetingoftheAssociationforComputationalLinguistics(Volume1:LongPapers),pp.7601–7614,2024.
[3]Wei,J.,Wang,X.,Schuurmans,D.,Bosma,M.,brianichter,Xia,F.,Chi,E.H.,Le,Q.V.,andZhou,D.Chainofthoughtpromptingelicitsreasoninginlargelanguagemodels.InAdvancesinNeuralInformationProcessingSystems,2022.
[4]DeepSeek-AI,Guo,D.,Yang,D.,Zhang,H.,etal.Deepseek-r1:Incentivizingreasoningcapabilityinllmsviareinforcementlearning,2025.URLhttps://arxiv.org/abs/2501.12948.
[5]Lake,B.andBaroni,M.Generalizationwithoutsystematicity:Onthecompositionalskillsofsequence-to-sequencerecurrentnetworks.InProceedingsoftheInternationalConferenceonMachineLearning,pp.2873–2882,2018a.
[6]Wang,B.,Deng,X.,andSun,H.Iterativelypromptpretrainedlanguagemodelsforchainofthought.InProceedingsofthe2022ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pp.2714–2730,2022.
[7]Zelikman,E.,Wu,Y.,Mu,J.,andGoodman,N.STar:Bootstrappingreasoningwithreasoning.InAdvancesinNeuralInformationProcessingSystems,2022.
[8]Liu,J.,Pasunuru,R.,Hajishirzi,H.,Choi,Y.,andCelikyilmaz,A.Crystal:Introspectivereasonersreinforcedwithself-feedback.InProceedingsofthe2023ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pp.11557–11572,2023.
[9]Li,Z.,Wallace,E.,Shen,S.迪士尼彩乐园lll,Lin,K.,Keutzer,K.,Klein,D.,andGonzalez,J.Trainbig,thencompress:Rethinkingmodelsizeforefficienttrainingandinferenceoftransformers.InProceedingsofthe37thInternationalConferenceonMachineLearning,pp.5958–5968,2020.
[10]Zhou,C.,Liu,P.,Xu,P.,Iyer,S.,Sun,J.,Mao,Y.,Ma,X.,Efrat,A.,Yu,P.,YU,L.,Zhang,S.,Ghosh,G.,Lewis,M.,Zettlemoyer,L.,andLevy,O.Lima:Lessismoreforalignment.InAdvancesinNeuralInformationProcessingSystems,2023a.
[11]Press,O.,Zhang,M.,Min,S.,Schmidt,L.,Smith,N.,andLewis,M.Measuringandnarrowingthecompositionalitygapinlanguagemodels.InFindingsoftheAssociationforComputationalLinguistics:EMNLP2023,pp.5687–5711,2023.
[12]Yang,S.,Gribovskaya,E.,Kassner,N.,Geva,M.,andRiedel,S.Dolargelanguagemodelslatentlyperformmulti-hopreasoning?,2024.URLhttps://arxiv.org/abs/2402.16837.
[13]Wang,B.,Yue,X.,Su,Y.,andSun,H.Grokkingofimplicitreasoningintransformers:Amechanisticjourneytotheedgeofgeneralization.InAdvancesinNeuralInformationProcessingSystems,2024a.
[14]Power,A.,Burda,Y.,Edwards,H.,Babuschkin,I.,andMisra,V.Grokking:Generalizationbeyondoverfittingonsmallalgorithmicdatasets,2022.URLhttps://arxiv.org/abs/2201.02177.
[15]Cabannes,V.,Arnal,C.,Bouaziz,W.,Yang,X.A.,Charton,F.,andKempe,J.Iterationhead:Amechanisticstudyofchain-of-thought.InAdvancesinNeuralInformationProcessingSystems,2024.
[16]Nostalgebraist.Interpretinggpt:Thelogitlens,2020.
[17]Pearl,J.Causality:Models,Reasoning,andInference.CambridgeUniversityPress,Cambridge,2009.ISBN9780521426085.
[18]Touvron,H.,Lavril,T.,Izacard,G.,Martinet,X.,Lachaux,M.-A.,Lacroix,T.,Roziere,B.,Goyal,N.,Hambro,E.,`Azhar,F.,etal.Llama:Openandefficientfoundationlanguagemodels.arXivpreprintarXiv:2302.13971,2023.
[19]Hao,S.,Sukhbaatar,S.,Su,D.,Li,X.,Hu,Z.,Weston,J.,andTian,Y.Traininglargelanguagemodelstoreasoninacontinuouslatentspace,2024b.URLhttps://arxiv.org/abs/2412.06769.
[20]Katz,S.,Belinkov,Y.,Geva,M.,andWolf,L.Backwardlens:Projectinglanguagemodelgradientsintothevocabularyspace.InProceedingsofthe2024ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,pp.2390–2422,2024.