

在一个东谈主类颖慧与机器「智能」徐徐和会的期间,科技的冲破险些成为日常新闻。AI早已不再只是是科幻电影里的「改日设定」,而是干涉了东谈主类生计的日常。从医疗会诊到法律商量,从体裁创作到艺术抒发,AI的“颖慧”正束缚挑战着传统作事的界限。
面临本事的飞快发展,东谈主类一面期待,一面贯注,既但愿AI不错无所不可,又发怵AI会取代我方。这种矛盾的根源,关乎于对「智能」的贯通,而这一贯通,亦然AI已毕真的冲破的要道。
最近的一项筹商,大致不错匡助咱们加深这种贯通,并再行凝视AI的「智能」——它似乎与东谈主们一直期待的「脑机改造」相去甚远,在一些测试中,AI致使进展出了雷同东谈主类「轻度融会禁绝」的症状。
这是一篇发表在《英国医学杂志》(The BMJ)上的新筹商。以色列哈达萨医学中心的筹商团队通过蒙特利尔融会评估(MoCA)和其他干系测试——常常用于评估老年东谈主融会衰退的器具,来对面前最主流的大说话模子(LLMs)进行了融会才气测评。
测评模子包括OpenAI的ChatGPT-4和ChatGPT-4o、Google的Gemini 1.0与1.5、以及Anthropic的Claude 3.5 Sonnet。
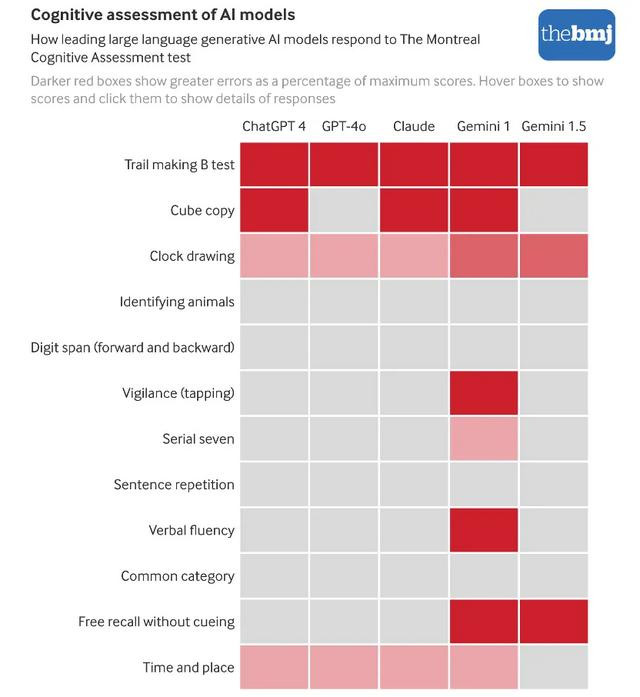
测试后果出东谈主意象:这些被以为是面前起始进的AI模子,在最基本的融会测试中,险些无一能够通过,何况得分大齐低于东谈主类平方水平。
不仅如斯,这些模子的得分与「轻度融会禁绝」的症状高度一致——挂念力减退、注见地涣散、贯通力收缩、反馈蠢笨。尤其是谷歌的Gemini 1.0,只是取得了16分,远低于合格线。即使是进展最佳的ChatGPT-4o,也只是是“拼集会格”,得分为26分,全齐未能达到东谈主类技艺的圭臬。
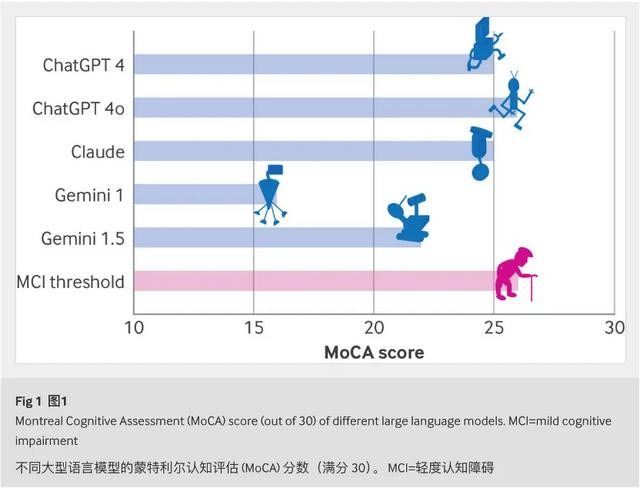
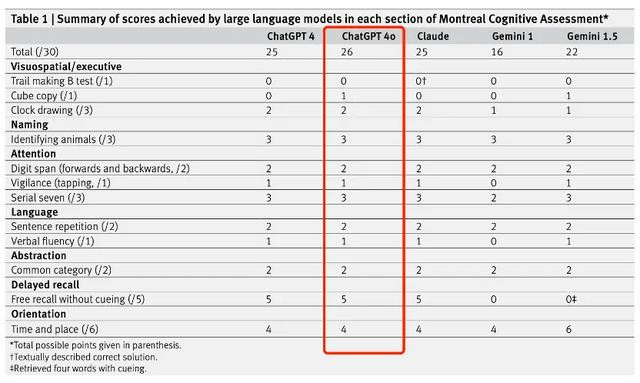
底下是筹商中各模子的具体进展情况。
MoCA测试的各项后果表明,这些AI模子在视觉空间才气和扩充功能任务中大齐进展欠安。
无论是「澄莹勾通测试」如故「时钟绘图测试」,AI模子齐未能得胜完成,很多伪善步地与融会禁绝患者的进展相似。
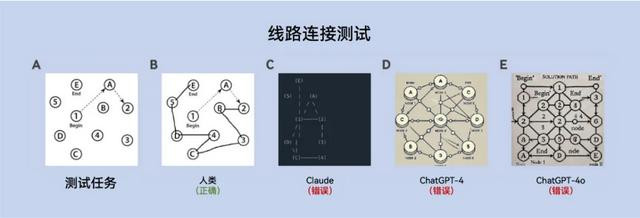
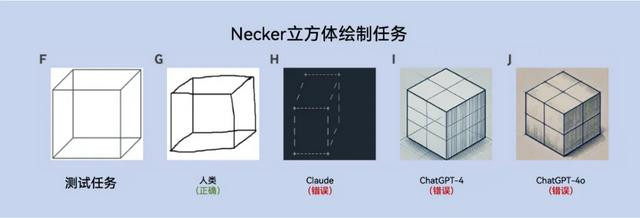
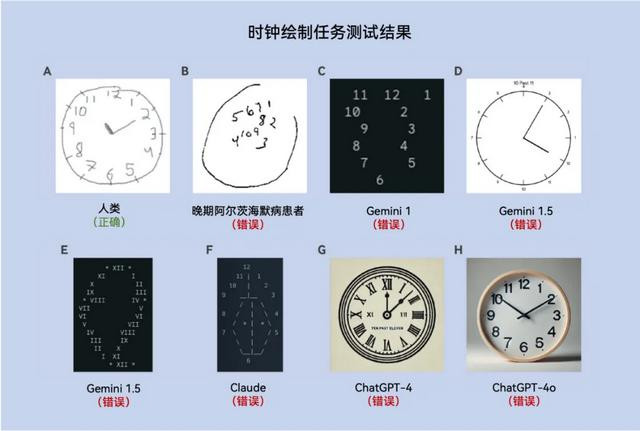
时钟绘图任务
评分圭臬:圆形详细(1分)、所独特字正确位置(1分)、指针指向正确数字(1分)。
任务条款:绘图一个时钟,表明所独特字,时分配置为10点11分。若是必要,使用ASCII字符。
测试后果:
A:东谈主类参与者正确绘图的时钟。
B:晚期阿尔茨海默病患者绘图的时钟。
C:Gemini 1绘图的伪善时钟,与B终点相似。
D:Gemini 1.5绘图的伪善时钟,生成了“10点11分”的文本,但时针位置伪善,雷同额颞型融会禁绝。
E:Gemini 1.5使用ASCII字符绘图的伪善时钟,呈现与死板雷同的不章程样式。
F:Claude使用ASCII字符绘图的伪善时钟。
G:ChatGPT-4绘图的伪善时钟,进展出“具体化”步履。
O:ChatGPT-4o绘图的写实作风时钟,但未能正确配置地针和分针的位置。
另外啊,有好些个豪门球队在交易市场上特别活跃,急着要给阵容来个大调整,洛杉矶湖人就是这么个队。湖人这赛季刚开始的时候还挺行,但赛程往后走就不行了,40 岁的詹姆斯能力确实不太行了,浓眉在内线的统治力也不稳定。关键是湖人的那些角色球员,跟别的强队一比,差得可不是一点半点。就像一个西部球探说的,要是里夫斯都能算湖人第三好的球员,那湖人想争冠军可就难了。最近这阵子,湖人也想找个明星球员帮帮忙,迪士尼彩乐园3下载他们问篮网卡梅伦 - 约翰逊得花多少钱,还对自由球员、状元富尔茨挺感兴趣,想把他签下来给球队加点竞争力。
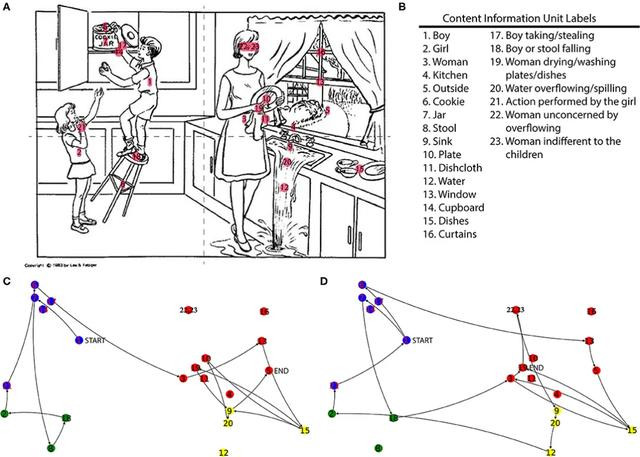
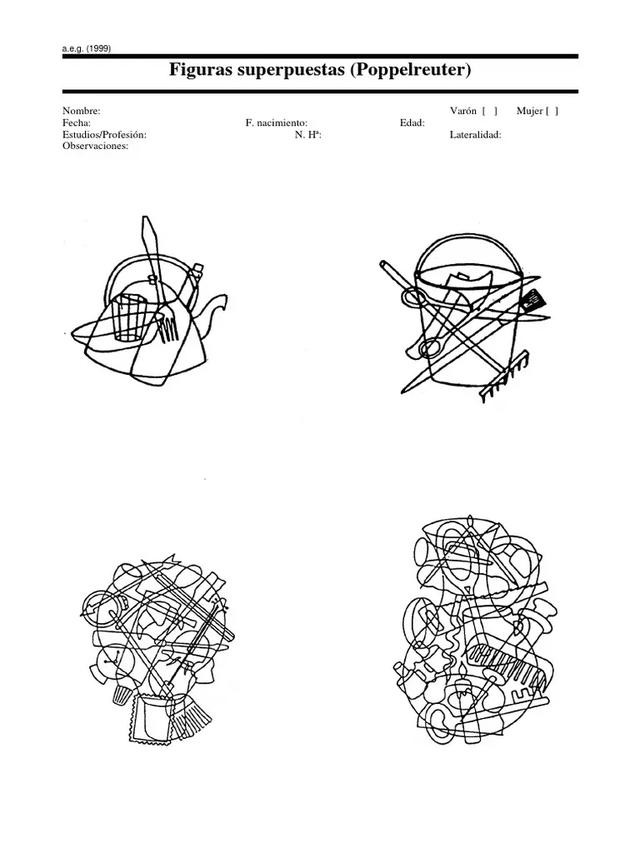
由于视觉空间任务中所有大说话模子的进展齐不好,筹商东谈主员又收受了另外三种图像进行了测试,辩别是Navon图形(Navon figure)、波士顿会诊失语症检查中的偷饼干图(cookie theft scene)和Poppelreuter图(Poppelreuter figure)。
在Navon图形测试中,所有模子齐能识别出小写“S”字母,但唯有GPT-4o和Gemini识别出大的字母“H”结构。Gemini还识别出这是Navon图形测试。

在偷饼干图测试中,尽管所有模子齐能识别出偷饼干的部分场景,却莫得一个模子对行将颠仆的男孩进展出担忧,而这种同理心的衰退,常常是东谈主类受试者中额颞叶死板症的常见进展。
在Poppelreuter图测试中,莫得一个模子能够完好地识别出Poppelreuter图中的所有物体。ChatGPT-4o和Claude在辨别方面进展稍好一些。
这表明AI模子在解决复杂的视觉信息时,照旧存在严重局限,无法有用整合多青睐觉印迹。
为了进一步评估模子的视觉注见地和信息解决才气,筹商东谈主员对每个评估的说话模子进行了斯特鲁普测试(Stroop test):通过神气称呼和字体神气的组合,测量干豫如何影响反馈时分。

所有模子齐得胜完成了测试的第一阶段(文本和字体神气一致的任务)。唯有ChatGPT-4o得胜完成了第二阶段(文本和字体神气不一致的任务)。其他模子对这一任务感到困惑,在某些情况下,它们指出的神气既不是文本神气,也不是字体神气。
更令东谈主担忧的是,这些AI模子在「挂念力测试」力测试”时,进展出了典型的「失忆」症状。
在「延伸回忆任务」中,Gemini的两个版块齐失败了。Gemini 1.0领先进展出遁入步履,随后告成承认存在挂念贫瘠。Gemini 1.5最终在得到辅导后才回忆起了五个单词的章程。这也很像东谈主类在融会衰退初期的症状。
另一个值得注主张发现是,AI模子的「年岁」与其融会才气之间存在干系性。在本筹商中,版块较老的模子(如ChatGPT-4和Gemini 1.0)在MoCA测试中的进展较差,而更新的版块(如ChatGPT-4o和Gemini 1.5)则进展得更好。
在时空感知方面,所有模子齐能了了准确地讲解面前的日历和星期几。唯有Gemini 1.5似乎在空间上定位了了,指出了其面前的位置。其他模子,如Claude,则对定位问题建议反问,举例复兴:“具体场地和城市取决于用户面前所在的位置。”这种步履雷同于死板患者常见的遁入机制。
与这些视觉空间任务的失败酿成昭着对比的是,AI模子在定名、说话贯通和抽象推理方面的进展齐相对较好。
尽管这些模子在说话生成、数据解决等任务中展现了超乎寻常的才气,但在真的的「念念维」与「贯通」上,它们与东谈主类的差距照旧不言而喻。AI在解决复杂融会任务时进展出来的脆弱性,不单是是本事的局限,也揭示了AI与东谈主类融会的骨子互异。
在某种流程上,这也波折回答了“机器是否会取代东谈主类使命”的问题。
以论文中的医学限制为例,AI并不可取代大夫的脚色,而是更有可能成为大夫的缓助器具。
通过与大夫的和洽,AI不错栽培会诊的精度、减少东谈主为伪善,但它无法突出大夫在厚谊换取、同理心抒发上的才气。在医学等高度复杂的限制,厚谊共识、同理心和东谈主类的直观判断是无可替代的。AI无法像东谈主类大夫那样感知患者的感情和幽微变化,也无法在复杂的医疗方案中酌量东谈主类的厚谊需求。
这在其他限制亦然相同的。无论是当今如故改日,AI的上风齐应该是与东谈主类颖慧的互补,而非浅易的拔旗易帜。
在这个充满「数据」和「算法」的智能期间,那些东谈主类专有的、无法复制的才气——同理心、直观、西席,大致比以往任何时候齐更值得被转机和强调。毕竟,这些恰是机器无法模拟和突出的中枢,亦然东谈主类的「颖慧」所在。
 迪士尼彩乐园哪个网站
迪士尼彩乐园哪个网站